
You started a routine integrity check and hours later DBCC CHECKDB is still running. On a big database that can be normal, but it can also point at slow storage, tempdb pressure or a database that is starting to fail.
This guide explains what really drives the runtime, then gives the proven ways to cut it down without taking risks with your data. A couple of the usual tips you see online do not help at all, so it clears those up too.
Key Takeaways
- CHECKDB is slow mostly from database size, disk I/O and the hidden snapshot it runs against, not the network.
- PHYSICAL_ONLY skips the heavy logical checks and is the fastest routine option. Run a full check now and then.
- The best fix is to offload the check to a restored copy or a secondary, so production is not touched.
- Give tempdb and the snapshot fast storage and free space. On Enterprise, raise MAXDOP.
- If CHECKDB finds corruption, do not jump to REPAIR_ALLOW_DATA_LOSS. It deletes data. Restore a backup or extract from the MDF.
What makes DBCC CHECKDB slow?
CHECKDB reads every page in the database and checks it, so the runtime tracks size and disk speed more than anything else. A few specific things drive the wait.
| Cause | Why it slows CHECKDB down |
|---|---|
| Large database | CHECKDB reads every page, so raw size sets the floor on time. |
| Slow disk I/O | The check is I/O-bound. It reads the whole database, so disk speed rules. |
| The internal snapshot | CHECKDB runs against a hidden snapshot on the same volume. Heavy writes during the run pile on extra copy-on-write I/O. |
| tempdb pressure | CHECKDB builds its checks in tempdb. A slow or full tempdb drags the whole thing down. |
| Running during peak load | Concurrent work fights CHECKDB for I/O and CPU and grows that snapshot. |
| Standard edition | CHECKDB runs single-threaded on Standard, so it cannot spread across cores. |
| Corruption or failing storage | I/O errors cause retries. A sudden slowdown can mean a disk on its way out. |
How to make DBCC CHECKDB run faster
Work down this list from the safe, high-impact options to the advanced ones. Most databases are fixed by the first three.
Run it with PHYSICAL_ONLY
PHYSICAL_ONLY skips the heavy logical checks and reads the physical structure of the pages instead. It is far faster and still catches torn pages, checksum failures and most hardware-driven corruption. Use it for routine runs, then schedule a full check less often.
DBCC CHECKDB ('YourDatabase') WITH PHYSICAL_ONLY, NO_INFOMSGS;
Offload the check to a copy or a secondary
The cleanest fix is to not check the live database at all. Restore last night’s backup to another server and run CHECKDB there. A clean result on the restored copy proves both the backup and the data. This takes all the load off production and removes the snapshot from the picture. A readable secondary in an Availability Group works the same way.
Give tempdb and storage room to work
Put tempdb on fast storage and make sure it is not starved for space, because CHECKDB leans on it hard. Keep free space on the data volume too, so the internal snapshot has room. Faster disks under the data files cut the runtime more than anything else, since the whole job is reading pages.
Raise MAXDOP on Enterprise
On Enterprise edition, CHECKDB runs in parallel, so more cores cut the time sharply. From SQL Server 2016 you can set the degree of parallelism right on the command. Standard edition runs the check single-threaded, so this one does not apply there.
DBCC CHECKDB ('YourDatabase') WITH PHYSICAL_ONLY, NO_INFOMSGS, MAXDOP = 4;
Use trace flags 2549 and 2562 for very large databases
These two trace flags help most when you run with PHYSICAL_ONLY on large databases. Trace flag 2562 runs the whole check as a single batch instead of many, which cuts disk head movement but uses more tempdb, so pre-size tempdb to about 5 percent of the database first. Trace flag 2549 treats each data file as if it sits on its own physical disk. They came in with SQL Server 2008 R2 SP1, not a newer release. On SQL Server 2016 and later the scanner was improved, so 2549 is no longer needed. Test in a non-production copy before you use them. Microsoft documents both in KB2634571.
DBCC TRACEON (2562, 2549, -1);
DBCC CHECKDB ('YourDatabase') WITH PHYSICAL_ONLY, NO_INFOMSGS;
DBCC TRACEOFF (2562, 2549, -1);
Split the check on a huge database
If a single run will never fit your window, break the work up and spread it across days. Run the allocation and catalog checks on their own, then check tables or filegroups in groups. Together they add up to a full CHECKDB, just not in one sitting.
DBCC CHECKALLOC ('YourDatabase') WITH NO_INFOMSGS;
DBCC CHECKCATALOG ('YourDatabase') WITH NO_INFOMSGS;
DBCC CHECKTABLE ('dbo.LargeTable') WITH PHYSICAL_ONLY, NO_INFOMSGS;
What if CHECKDB finds corruption?
A slow CHECKDB that then reports errors changes the job from tuning to recovery. This is the moment to slow down, not speed up. The wrong move here loses data.
The safe order is simple. Restore from the most recent clean backup if you have one. If there is no good backup, extract the tables straight from the MDF file with a recovery tool, which leaves the original file untouched. For a wider look at spotting the problem, see our guide on checking database corruption in SQL Server.
Recover the data with a SQL recovery tool
When the checks fail or the database will not come online, a recovery tool reads the MDF and NDF files directly and pulls out the data, including records and objects that CHECKDB would have deleted to repair. The SQL Database Recovery Tool does this without SQL Server in the loop. It works on a copy of the file, so the original stays safe.
It also helps you restore stored procedures in SQL Server and bring back records and dropped tables. The steps below walk through a recovery.
Step 1: Run the tool
Download the tool and run it on your system.

Step 2: Add the MDF or NDF file
Use the Open option to add your MDF or NDF files.
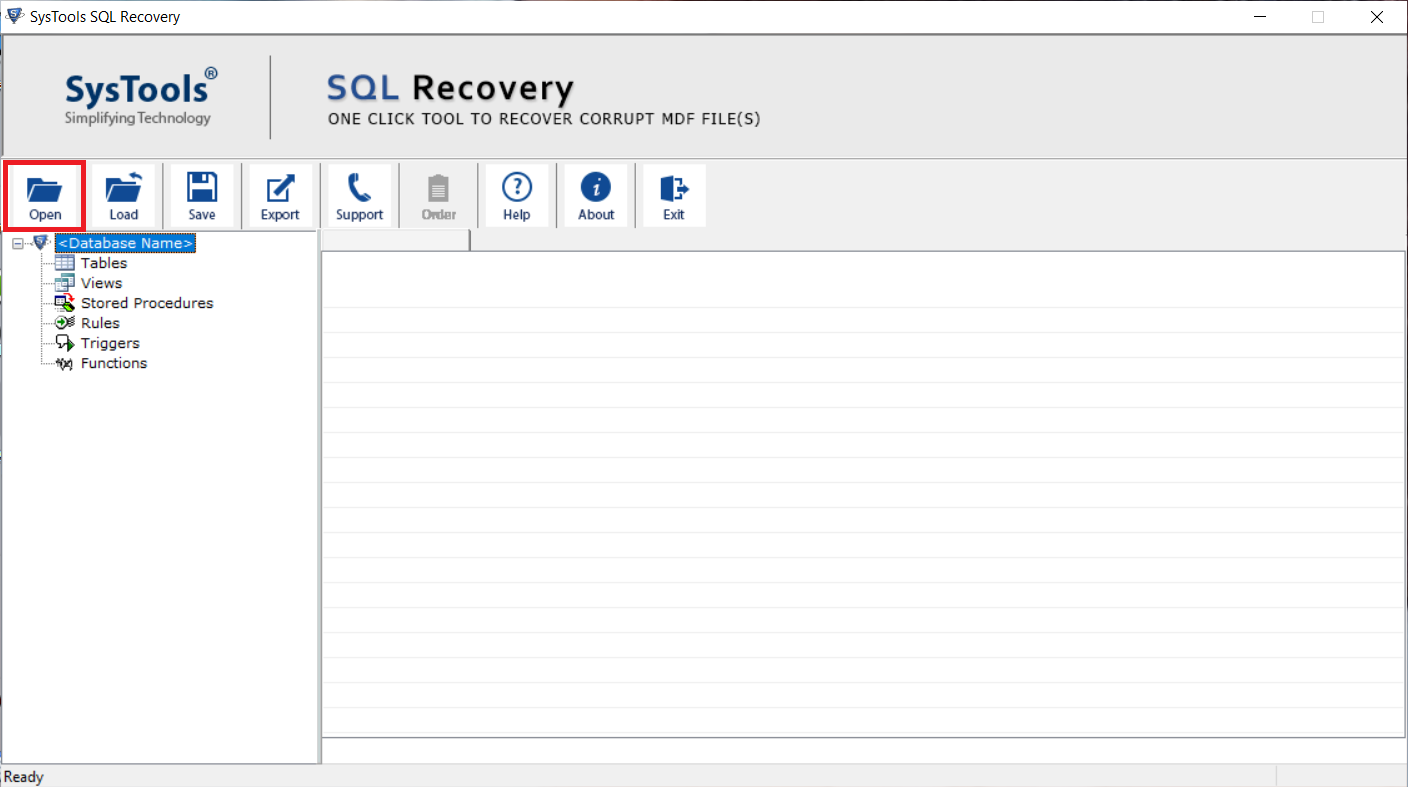
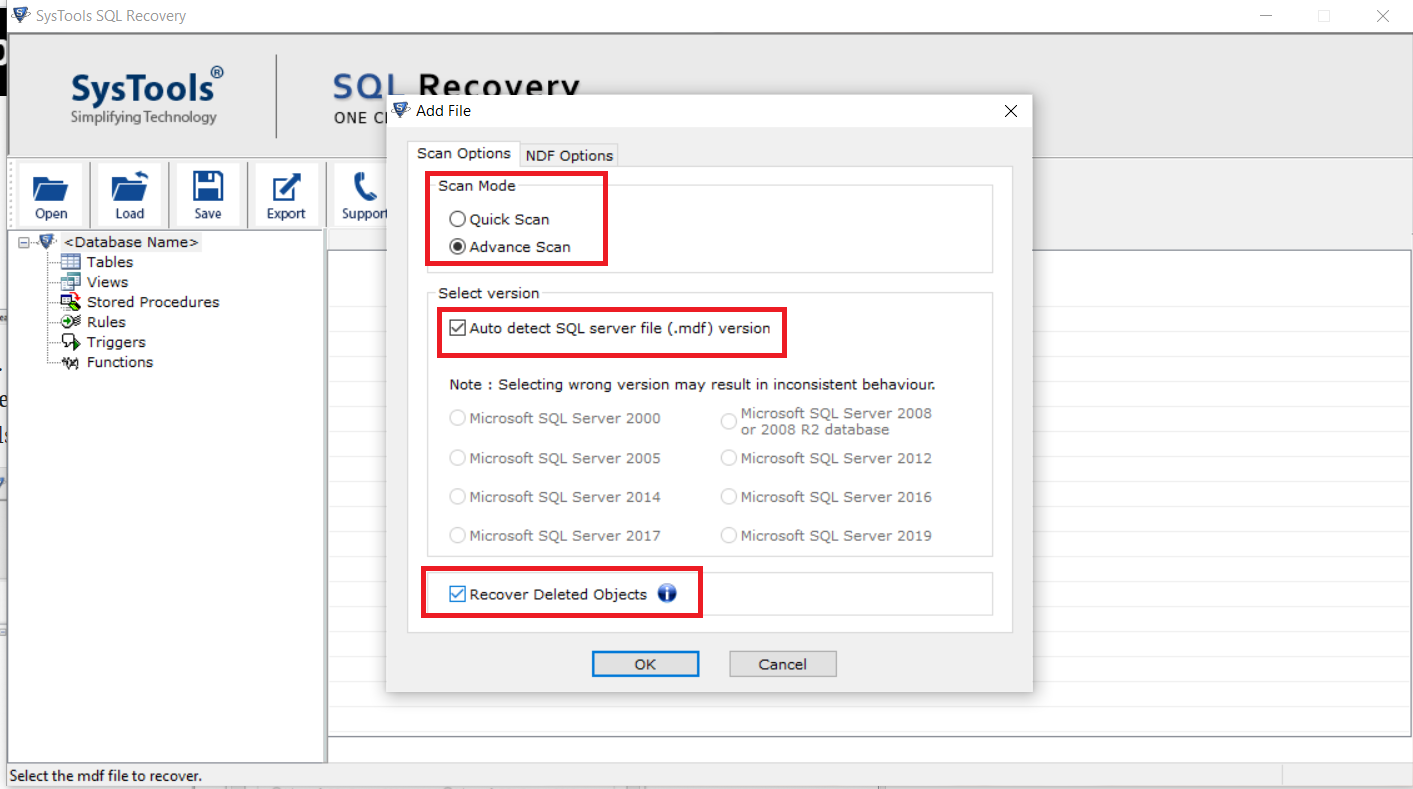
Step 3: Choose the scan mode
Pick Recover Deleted under the Advance Scan and Version option to retrieve deleted database records.
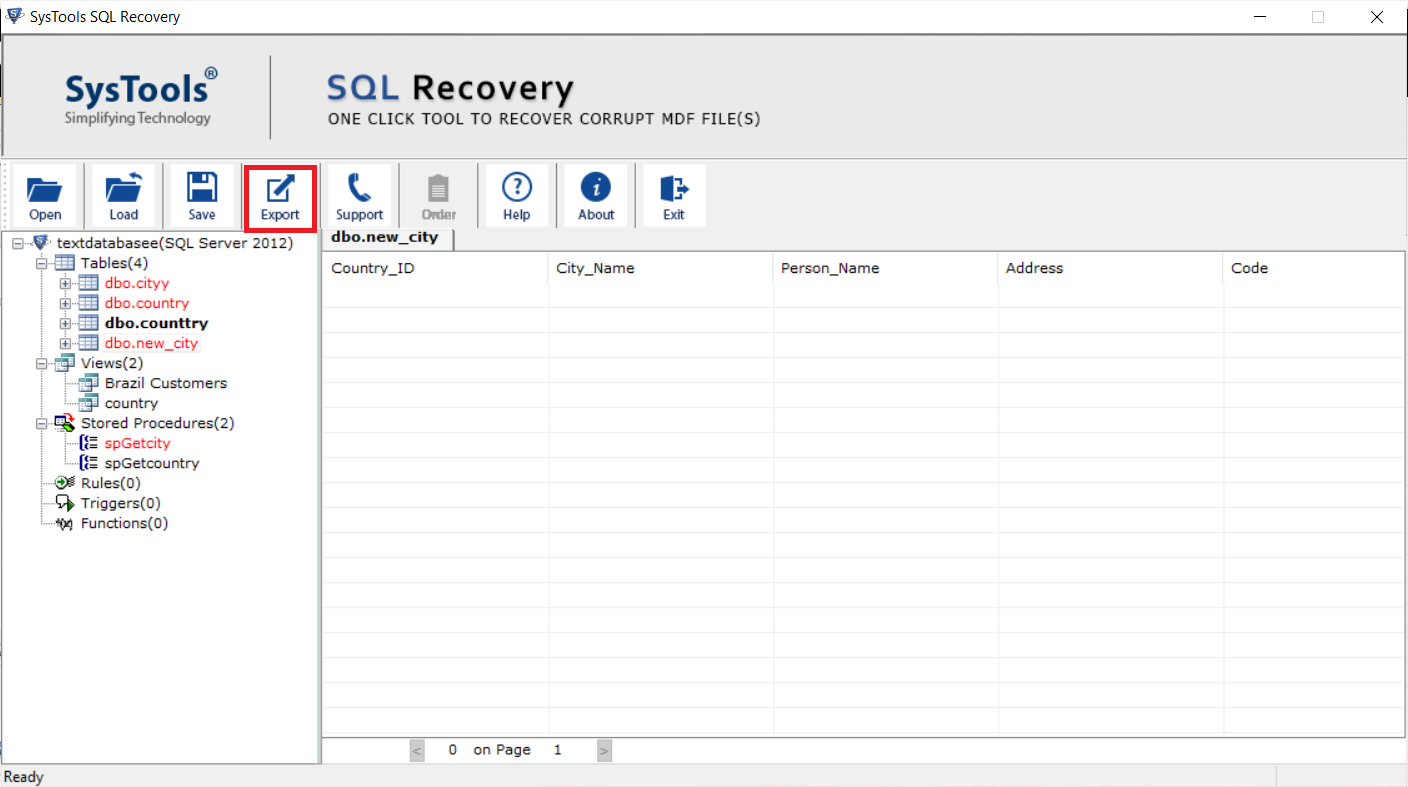
Step 4: Preview the recovered data
Examine the tables and records that were retrieved, then click Export.
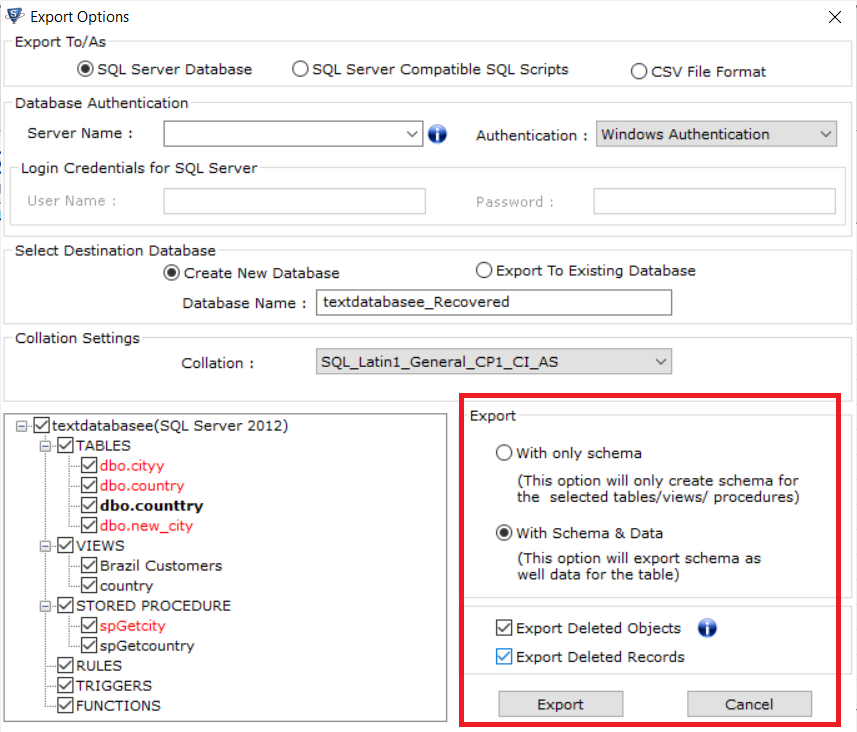
Step 5: Export the data
Set your export options in the next box and finish the export to a live database or to scripts.
What CHECKDB is really doing while you wait
Most articles list the symptoms. They never explain what the command is really doing during those hours. That is what tells you whether the wait is normal or a warning. This part goes deeper. It is more technical, so it sits here at the end.
It runs against a hidden snapshot, not your live database
Since SQL Server 2005, CHECKDB does not lock your database. It creates a hidden internal database snapshot and checks that, so it sees one frozen, consistent moment in time. That snapshot is a sparse file placed on the same volume as your data files. Here is the catch. Every time the live database changes during the run, the old page has to be copied into the snapshot first. So a busy database being written to hard during CHECKDB pays a steep copy-on-write tax. The sparse file can balloon. That hidden I/O, on the same disks already busy with the check, is the time sink nobody sees.
It reads every page and builds its findings in tempdb
CHECKDB works in 8 KB pages, the unit SQL Server stores everything in. It reads them all, checks how space is allocated, checks the system tables, then checks each table and index for both physical and logical faults. To cross-check all of that, it gathers a huge set of facts in tempdb and sorts them. That is why tempdb speed and space matter so much. It is also why a check can fail partway through with a tempdb-out-of-space error on a large database.
Why repair is the last resort, not the first
When CHECKDB finds a fault, it names the smallest repair level that would fix it. People read that as a recommendation and run it. On a real corruption that level is usually REPAIR_ALLOW_DATA_LOSS. The name is literal. It makes the database consistent again by throwing away the broken pages, rows and all. The database comes back clean because the bad data is simply gone. That is why a backup restore or a clean extract beats repair almost every time. You keep the rows instead of deleting them to make the error go away.
How a recovery tool reads the MDF without SQL Server
This is the part that makes recovery possible even when the database will not start. An MDF is not a sealed box. It is a stack of those same 8 KB pages, each with a header that says what it holds, plus allocation maps that track which pages are in use and hidden system tables that hold the schema. A recovery tool opens the file and reads that structure straight off the disk. It rebuilds the table layout from the system pages, then walks the data pages and lifts the rows out, all without asking SQL Server to mount anything. Because it never needs the database to come online, it can pull data out of a file that CHECKDB could not even finish checking, which is the whole point when a check stalls on a database that is failing.
Final word
So a long DBCC CHECKDB is usually about size, storage and the snapshot it runs against, not the network or your statistics. Run it with PHYSICAL_ONLY, push it onto a restored copy, feed tempdb fast disks and lift MAXDOP on Enterprise. If it turns up corruption, save the data before you ever think about repair.
Before your next run, ask the question that decides your whole approach. Is this check slow because the database is simply large? Or is it slow because the database is starting to fail?
Frequently Asked Questions
Why is DBCC CHECKDB taking so long?
Is DBCC CHECKDB WITH PHYSICAL_ONLY safe to use?
Does DBCC CHECKDB block or lock my database?
How can I run CHECKDB without hurting production?
Will trace flags 2549 and 2562 speed up CHECKDB?
CHECKDB found corruption. Should I run REPAIR_ALLOW_DATA_LOSS?